
The Agent Framework Gap: Part 3 - Why It Exists and What You Give Up
Hi All,
I keep thinking the same question:
“Why is Python so far ahead on agent frameworks? Did R just miss the boat?”
The answer is more interesting than “yes, R is behind.” Let me walk you through why this gap exists — and more importantly, what you actually give up with each approach. Because here’s the thing: there’s no free lunch. Python’s speed comes with a cost. R’s transparency comes with a cost. The question is which cost you’re willing to pay.
The Cultural Divide
After working in both ecosystems, I’ve noticed something fundamental:
Python developers build for:
- Scalability
- Deployment
- Integration with web services
- “Ship it now, optimize later”
R developers build for:
- Reproducibility
- Statistical validity
- Audit trails
- “Get it right, then ship”
Those priorities shape what gets built. When LangChain came out, Python developers saw an opportunity: “We can automate workflows with LLMs!” They built agents that were fast, flexible, and… hard to audit. R developers saw the same thing and asked: “How do we prove what happened? How do we reproduce this? How do we explain it to a regulator?”. The answer wasn’t “just use LangChain.” It was “we need something different.”
The Technical Debt Problem
Here’s the thing about Python’s agent frameworks: they’re built on Python’s strengths. Python’s OOP model encourages mutation; R’s functional model enforces immutability. Neither is better — they lead to different architectures with different costs.
Python’s Hidden Costs
When you use LangChain or AutoGen, you get:
- Fast development
- Huge ecosystem
- Pre-built templates
- Community support
But you also get:
1. Opaque State
What happened inside? The LLM was called. Tools were executed. State was mutated. But where’s the record? You’re digging through logs trying to reconstruct the execution path. Or you’re hoping the framework captured everything. In a regulated environment, that’s a problem. We are getting tracebility as a part of managed service.
2. Mutable State
The state changes in place. If something goes wrong, you can’t rewind. You can’t replay. You can’t prove what the state was at step 3 vs step 4. For debugging, that’s painful. For compliance, that’s unacceptable.
3. Implicit Dependencies
The result depends on agent.config. But where’s that config stored? In the agent’s internal state. How do you capture it for reproducibility? You need to manually extract it. Or hope you documented it. Or hope you didn’t change it between runs.
R’s Hidden Costs
When you use ellmer or build your own functional agent, you get:
- Transparent state
- Immutable transformations
- Full audit trails
- Reproducibility by design
But you also get:
1. More Boilerplate
run_agent <- function(input, state) {
state |>
add_message(input, timestamp = Sys.time()) |>
plan_step() |>
execute_tools() |>
update_state(timestamp = Sys.time())
}
add_message <- function(state, input, timestamp) {
new_history <- c(state$history, list(
list(type = "input", content = input, timestamp = timestamp)
))
state$history <- new_history
state
}
plan_step <- function(state) {
plan <- list(step = "analyze", confidence = 0.95)
state$metadata$last_plan <- plan
state
}
That’s a lot of code for “call the LLM and get a result.”
In Python, that’s three lines with LangChain. You’re trading speed of development for clarity of execution.
2. Smaller Ecosystem
Want to connect to a custom API? There’s probably a LangChain integration already. Want to use a specific vector database? LangChain has it. AutoGen has it. LlamaIndex has it.
In R? You’re writing the integration yourself. That’s not a dealbreaker. But it’s real.
3. Steeper Learning Curve
Functional programming isn’t intuitive for everyone. The pipe operator (|>) helps. But you still need to think in terms of transformations, not mutations.
# This is R-native
state |>
add_message(input) |>
call_llm() |>
save_audit()
# This is what people expect
state = add_message(state, input)
state = call_llm(state)
save_audit(state)
Both work. The first looks weird if you’ve never seen it.
4. Less “Batteries Included”
Python frameworks come with:
- Pre-built agents
- Memory management
- Tool registries
- Multi-agent orchestration
R gives you:
ellmerfor LLM tool callingtidyversefor data manipulation- Your own orchestration logic
You’re building more from scratch.
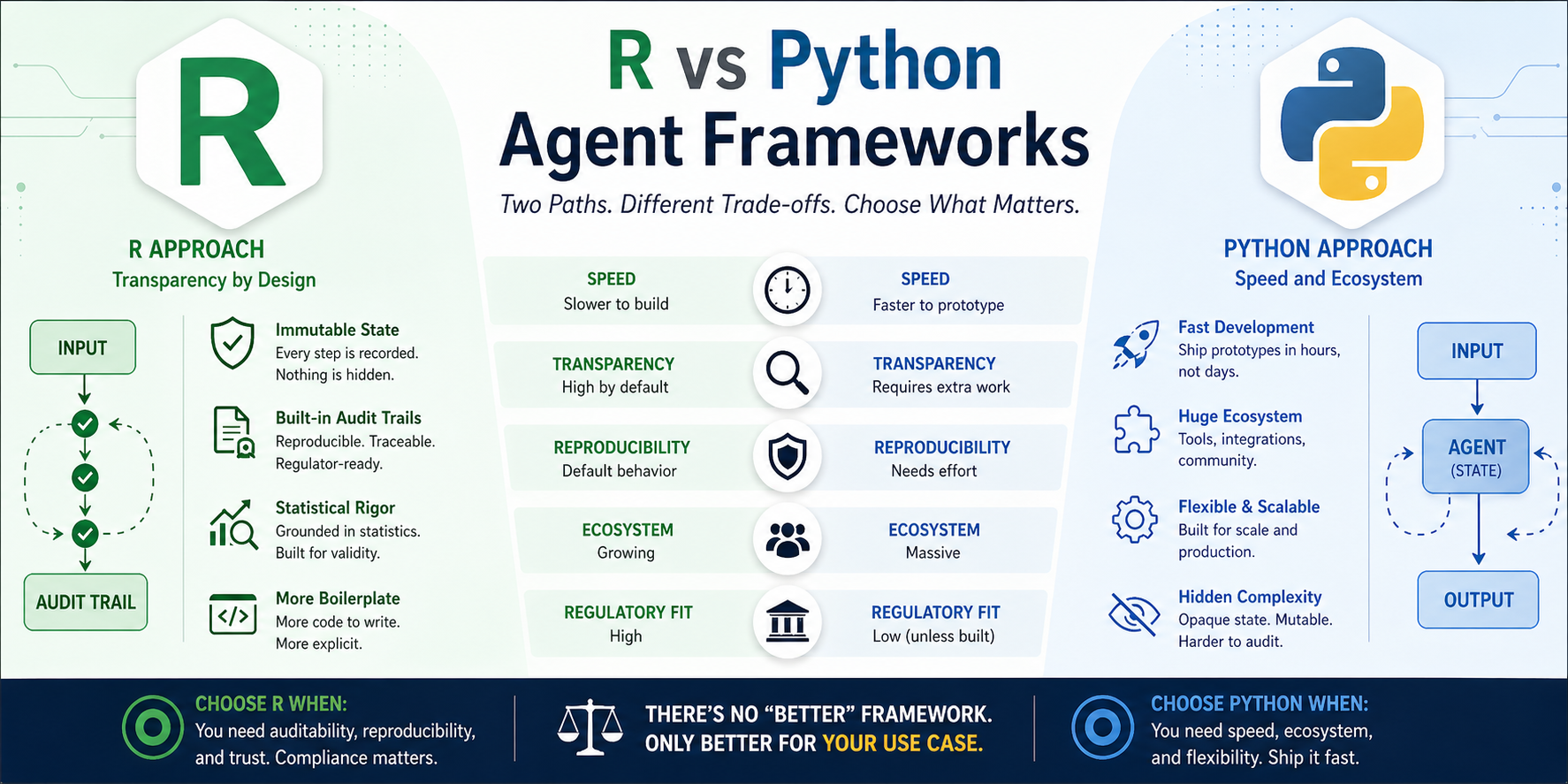
The Cost Matrix
Let me make this concrete:
| Factor | Python Agent | R Agent |
|---|---|---|
| Time to first prototype | 1-2 hours | 1-2 days |
| Time to production | 2-4 weeks | 4-8 weeks |
| Audit trail effort | Add logging manually or part of harness | Built-in by design |
| Reproducibility | Requires extra work | Default behavior |
| Debugging complexity | High (hidden state) | Low (explicit state) |
| Team learning curve | Low (everyone knows OOP) | Medium (functional is new) |
| Ecosystem support | Massive | Growing |
| Regulatory readiness | Low (unless you build it) | High (by design) |
The trade-off is clear:
- Python wins when you need speed, ecosystem, and don’t need to prove what happened.
- R wins when you need auditability, reproducibility, and can afford the extra development time.
When Each Makes Sense
Let me be specific about use cases:
Use Python Agents When:
- Building a startup MVP — Speed matters more than audit trails
- Internal automation — No regulatory requirements
- Rapid prototyping — You’re testing ideas, not shipping production
- Consumer-facing apps — Users care about features, not reproducibility
- Research exploration — You’re experimenting, not validating
Use R Agents When:
- Clinical trials — FDA requires ALCOA+ compliance
- Financial reporting — SEC requires audit trails
- Healthcare analytics — HIPAA requires traceability
- Regulated industries — Anywhere compliance matters
- Long-term research — You need to reproduce results in 6 months
The Package Ecosystem Effect
Let me be specific about the network effects:
Python:
- 400,000+ packages on PyPI
- AutoGen, CrewAI, LangGraph all built by teams at Microsoft, Google, startups
- Default choice for ML engineering roles
R:
- 19,000+ packages on CRAN
tidyllm,chattrare community experiments- Default choice for statisticians, not ML engineers
When you’re a startup building an agent framework, you choose Python. Why? Because that’s where the engineers are. That’s where the funding is. That’s where the “AI engineer” job postings are. R becomes a niche. Not because it’s worse — because it’s different.
The “Good Enough” Problem
Here’s something I won’t hear in R communities:
For most use cases, Python’s agents are “good enough.”
If you’re building a chatbot for a startup? LangChain works. If you’re prototyping an AI feature? AutoGen works. If you’re doing internal automation? CrewAI works.
The auditability problem only matters when:
- You’re in a regulated industry (pharma, finance, healthcare)
- You need to explain decisions to auditors
- You need to reproduce results months later
For 90% of AI applications, those requirements don’t exist. So Python’s approach wins on speed and ecosystem.
For the other 10% (the regulated stuff), R’s approach is better ( we can build the auditability around in Python easily now). But that 10% is a smaller market.
The Open Source Funding Gap
Let me be blunt about money:
LangChain raised $M in funding. AutoGen is backed by Microsoft Research. CrewAI has venture backing.
ellmer is maintained by Posit. tidyllm is a community experiment. chattr is a GitHub repo with few hundred stars.
That’s not an accident. It’s the result of where venture capital flows. AI agents are hot. But “AI agents for pharma compliance” is not a hot pitch deck (yet!). “AI agents for customer service” is. So Python gets the frameworks. R gets… what we can build in our spare time.
The Functional Programming Hurdle
Here’s the thing about R’s functional model: it’s harder to learn.
If you’ve never done functional programming, this looks weird:
state |>
add_message(input) |>
plan_step() |>
execute_tools() |>
update_state()
You’re passing state through a pipeline. Each function returns a NEW state. Nothing is mutated.
Compare to Python:
state["history"].append(input)
state = plan_step(state)
state = execute_tools(state)
Wait, that’s still functional. Let me show you the OOP way:
class Agent:
def run(self, input):
self.history.append(input) # Mutation!
result = self.llm.generate(input)
self.last_result = result # Mutation!
return result
That’s the default Python style. And it’s what most developers expect. R’s functional approach requires a mindset shift. It’s more verbose. It’s more explicit. But it’s also more predictable. The learning curve slows adoption.
What’s Actually Happening Now
I’m watching the ecosystem evolve. Here’s what I see:
- 1. Python is maturing. Early LangChain was buggy and opaque. Newer frameworks (LangGraph, LlamaIndex) are more explicit about state.
- 2. R is catching up.
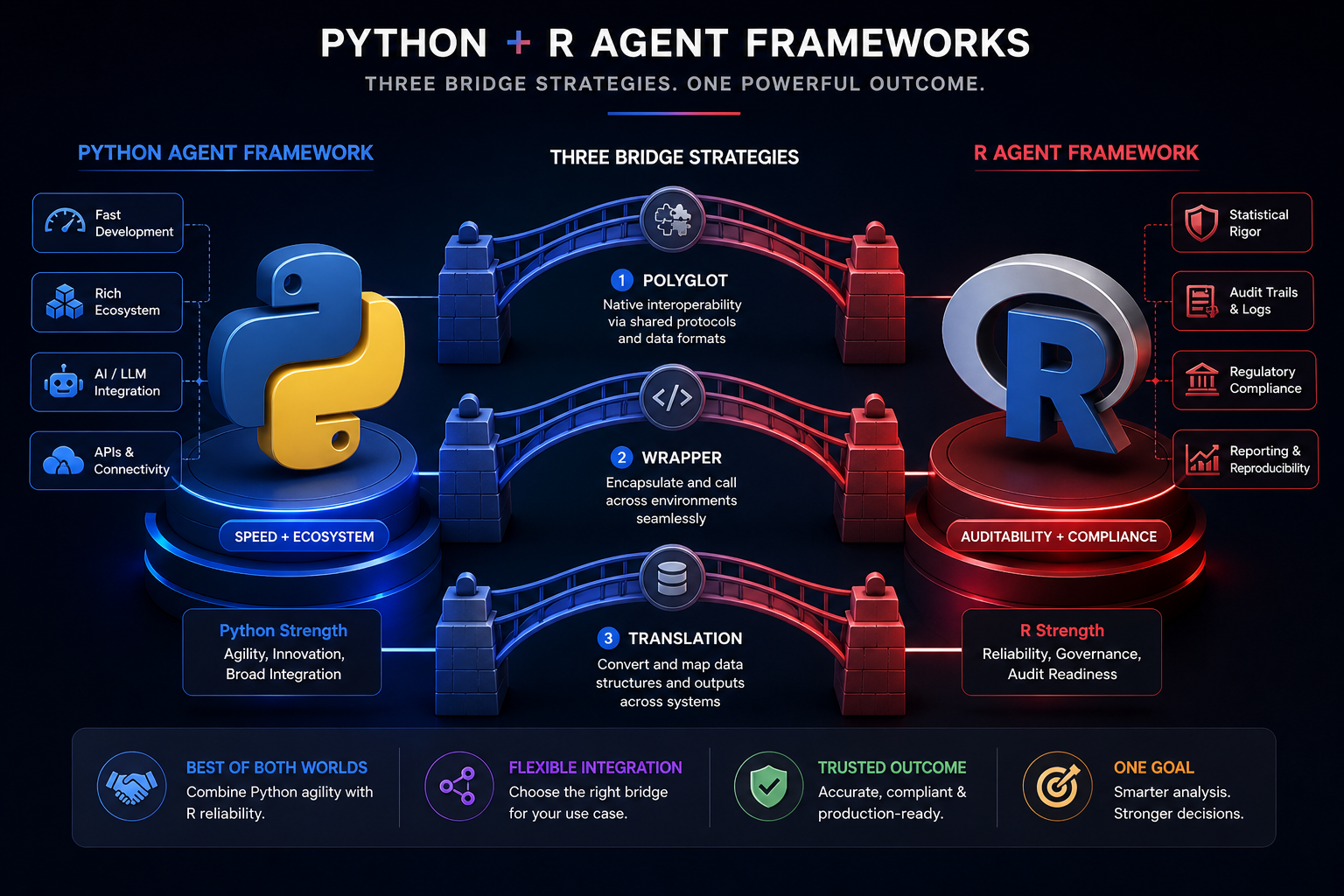
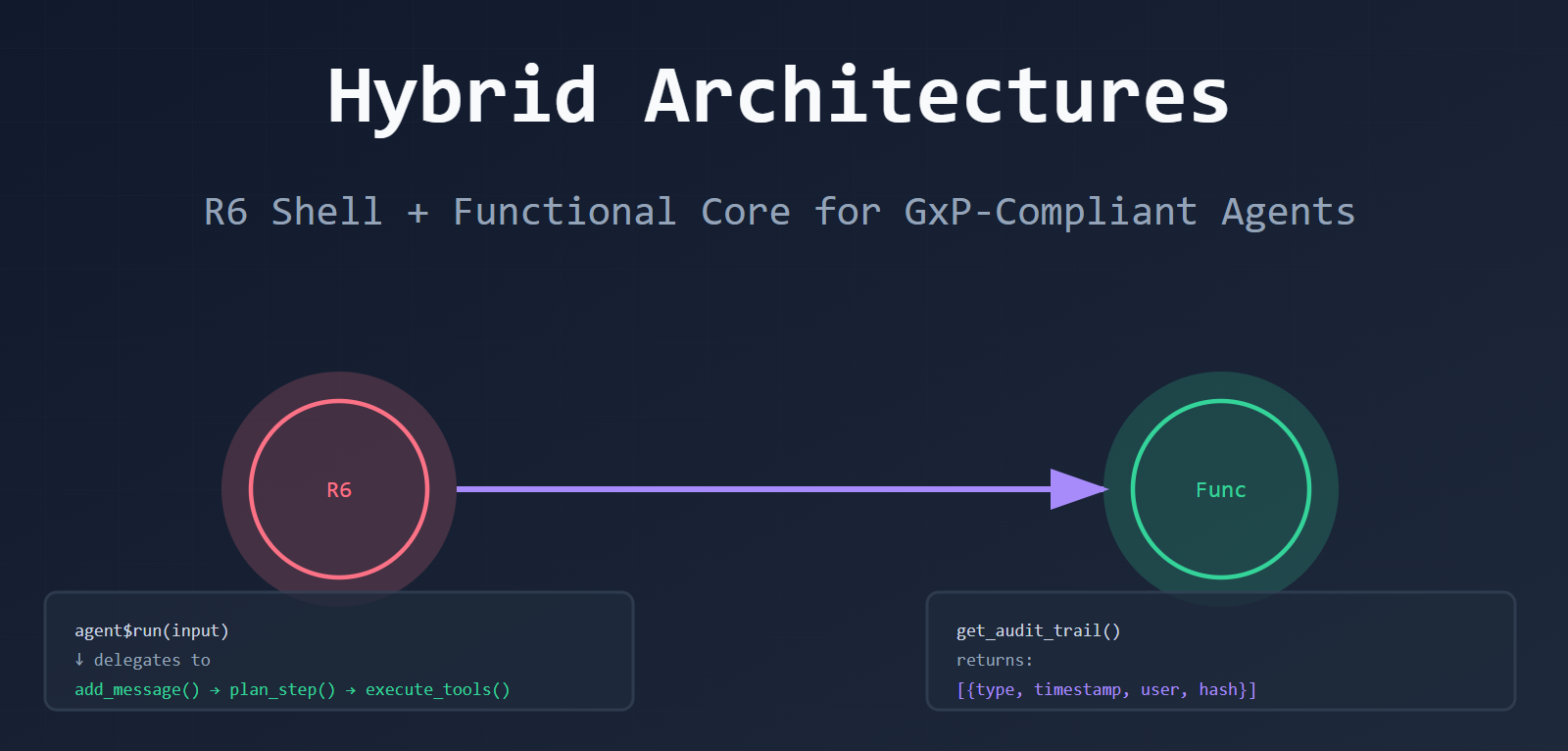
ellmeris production-ready.chattradds audit trails.TheOpenAIRbrings OpenAI compatibility. - 3. Hybrid patterns are emerging. R6 shells + functional cores. The best of both worlds.
- 4. The gap is narrowing. Not closing, but narrowing. R-native solutions are appearing.
The Real Question
What’s your actual requirement?
- If you need to prove what happened, Python’s agents will fight you every step of the way. You’ll add logging, capture state, write tests. You’re fighting the framework.
- If you need to ship fast and iterate, R’s agents will slow you down. You’re writing more code, managing state explicitly, thinking in functional terms. You’re fighting the culture.
Neither is wrong. But you need to know which fight you’re in.
The Bottom Line
There’s no “better” framework. There’s only “better for your use case.”
If you’re building a chatbot for your startup? Use Python. Ship fast. If you’re analyzing clinical trial data for the FDA? Use R. Be auditable.
The gap isn’t a problem. It’s a choice and maybe that’s the point. If R had the same agent frameworks as Python, we’d have the same problems. Opaque state. Mutable history. No audit trails. The fact that R is different means we have a choice. We can use Python’s speed when it makes sense. We can use R’s transparency when it matters.
Thank you!!
Leave a comment