
The Agent Framework Gap: Part 2 — Hybrid Architectures
Hi All,
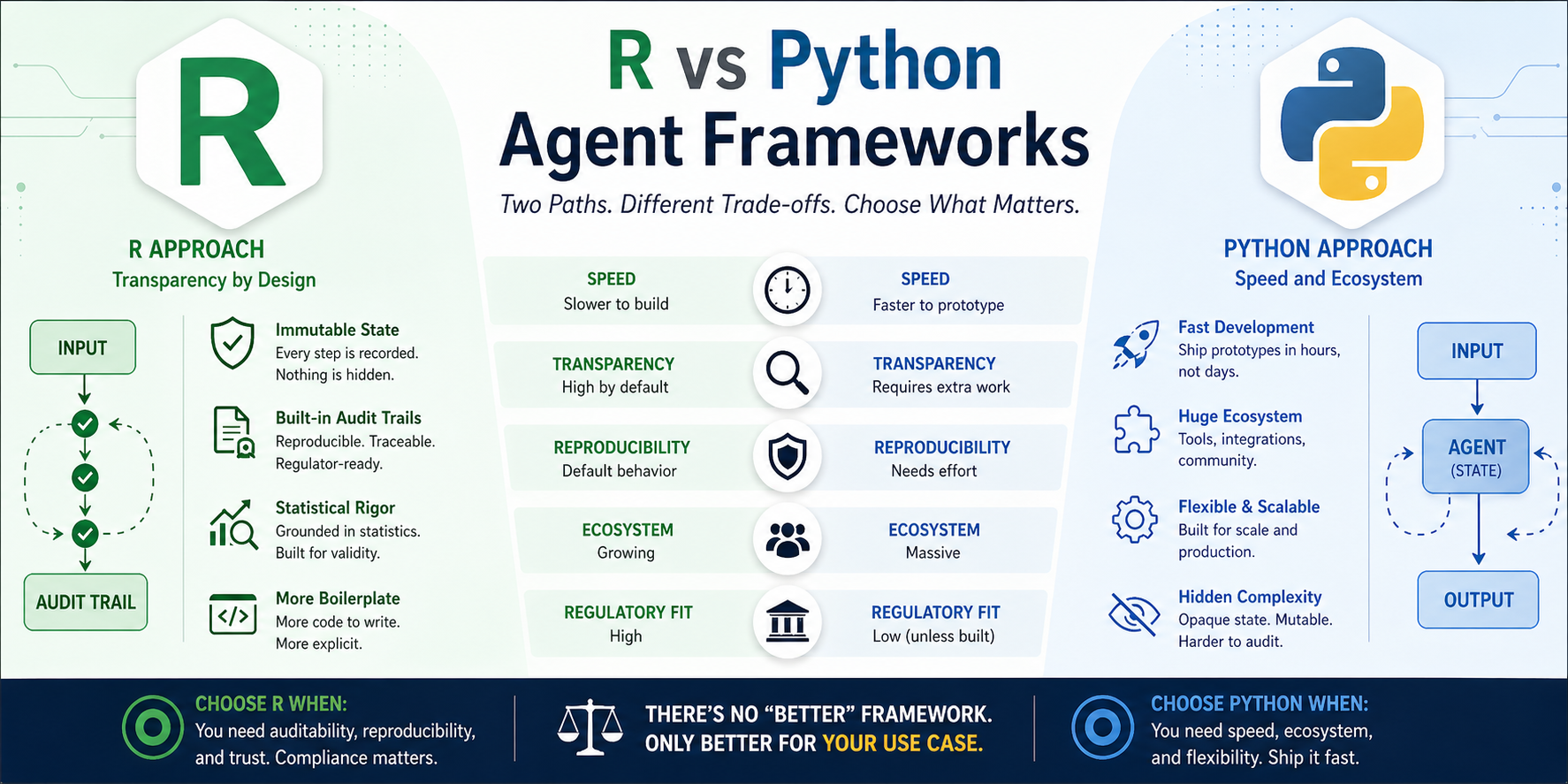
In the previous post, we looked at the agent framework gap between Python and R. The conclusion? It’s not a problem — it’s a trade-off.
But here’s the thing: what if you don’t have to choose? What if you could have Python’s ease of use and R’s auditability? What if you could build an agent that’s both fast to develop and FDA-ready?
That’s where hybrid architectures come in.
The Problem We’re Solving
Let’s be honest about the pain points:
Python agents are powerful but opaque. State lives inside objects. Methods mutate that state. When the FDA asks “show me the exact execution path,” you’re digging through logs trying to reconstruct what happened.
Pure R agents are transparent but require more work. You’re building the orchestration yourself. No pre-built templates. No “just works” multi-agent patterns.
The hybrid approach says: why not both?
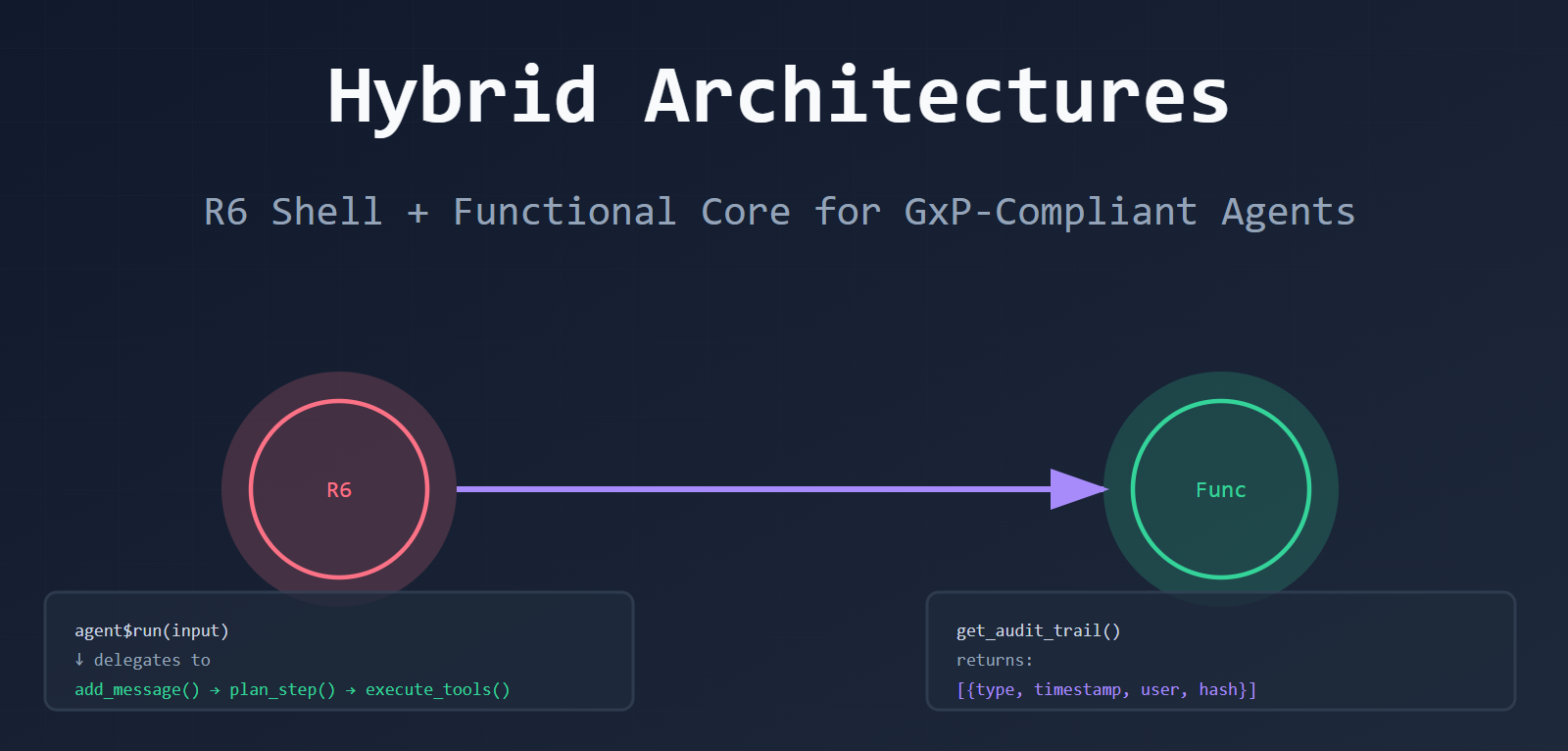
The Hybrid Pattern: R6 Shell + Functional Core
Here’s the idea:
- R6 layer (the shell): Provides a familiar OOP interface.
agent$run(),agent$get_audit_trail(). Easy to use. - Functional core (the engine): Pure functions that transform state.
add_message(),plan_step(),execute_tools(). Transparent and auditable.
Think of it like a car:
- The dashboard (R6) is what you interact with. Buttons, gauges, familiar controls.
- The engine (functional) is what actually makes it work. Clean, predictable, no surprises.
You get the best of both worlds.
What It Looks Like in Code
Let me show you what this actually looks like. No hype, just code:
# The R6 Shell (User Interface)
Agent <- R6::R6Class("Agent",
public = list(
state = NULL,
initialize = function() {
self$state <- list(
history = list(),
results = list(),
metadata = list(created = Sys.time())
)
},
run = function(input) {
# Delegate to functional core
self$state <- agent_loop(input, self$state)
return(self$state$result)
},
get_audit_trail = function() {
# Full execution history, exposed on demand
return(self$state$history)
}
)
)
# The Functional Core (Audit Trail)
agent_loop <- function(input, state) {
state |>
add_message(input, timestamp = Sys.time()) |>
plan_step() |>
execute_tools() |>
update_state(timestamp = Sys.time())
}
add_message <- function(state, input, timestamp) {
new_history <- c(state$history, list(
list(type = "input", content = input, timestamp = timestamp)
))
state$history <- new_history
state
}
plan_step <- function(state) {
# Pure function, returns new state
plan <- list(step = "analyze", confidence = 0.95)
state$metadata$last_plan <- plan
state
}
execute_tools <- function(state) {
# Tool calls logged to state
tool_result <- list(data = "analysis results")
state$results <- c(state$results, list(tool_result))
state
}
update_state <- function(state, timestamp) {
state$metadata$last_update <- timestamp
state$result <- state$results[[length(state$results)]]
state
}
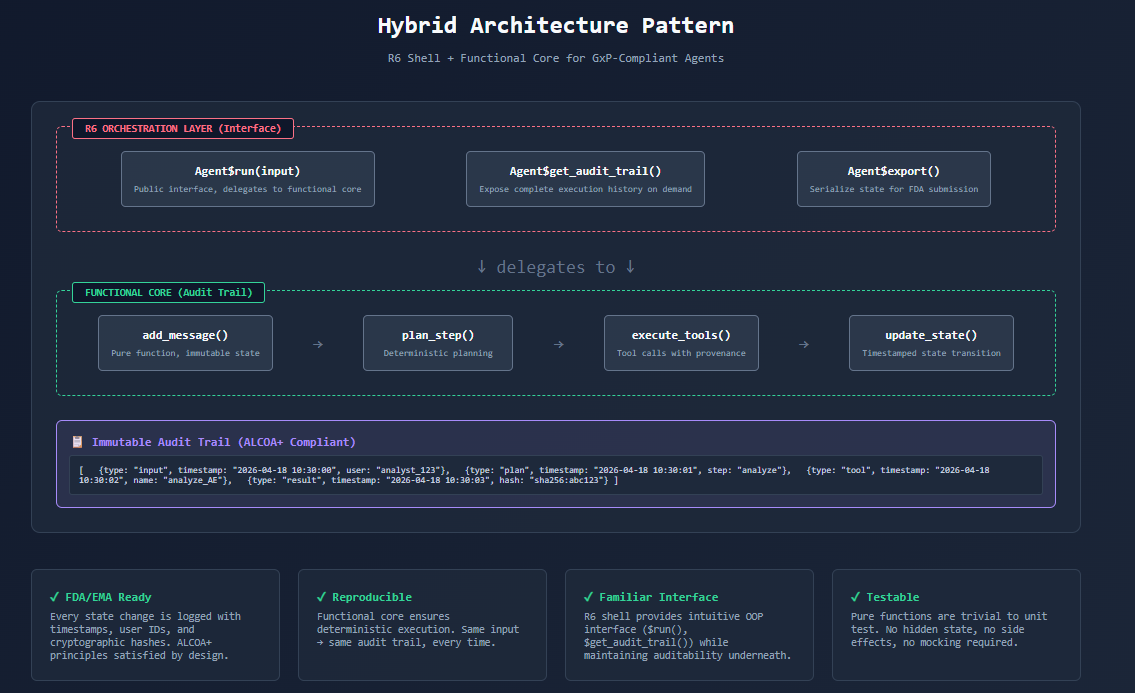
That’s it. The R6 class gives you a familiar interface. The functional core gives you a complete audit trail.
Why This Matters for Pharma
Let me be specific about why this pattern matters in regulated industries.
FDA’s ALCOA+ principles require data to be:
- Attributable — Who generated it? (User ID captured at input)
- Legible — Can it be read? (Clear function signatures)
- Contemporaneous — Recorded at time of work? (Timestamps on every step)
- Original — First capture preserved? (Immutable state history)
- Accurate — Error-free? (Validated transformations)
- Complete, Consistent, Enduring, Available — All of the above
With the hybrid pattern, each principle is satisfied by design:
# Every state change is logged
audit_trail <- agent$get_audit_trail()
#> [
#> {type: "input", content: "Analyze AE data", timestamp: "2026-04-18 10:30:00"},
#> {type: "plan", step: "analyze", timestamp: "2026-04-18 10:30:01"},
#> {type: "tool", name: "analyze_adverse_events", timestamp: "2026-04-18 10:30:02"},
#> {type: "result", data: {...}, timestamp: "2026-04-18 10:30:03"}
#> ]
The Trade-Off (There’s Always One)
Nothing’s free. Here’s what you give up with the hybrid approach:
- Complexity: You’re maintaining two layers. R6 + functional. More code to test.
- Performance: Slight overhead from state copying (immutability has a cost).
- Learning curve: Your team needs to understand both OOP and functional patterns.
But here’s the counterpoint:
- Regulatory risk: If you’re in pharma, the cost of non-compliance is way higher than the cost of extra code.
- Reproducibility: When you need to reproduce an analysis six months later (because the FDA asked), the functional core makes that trivial.
- Maintainability: Pure functions are easier to test than hidden state mutations.
The trade-off makes sense when your use case demands it.
What’s Possible Today
You don’t need to wait for new packages. This is buildable today with:
R6— For the orchestration layer (built into base R)ellmer— For LLM tool callingtidyverse— For pipe-friendly state transformationswaldo— For comparing state snapshots (testing)
Here’s a minimal working example you can copy-paste:
library(ellmer)
library(R6)
# Functional core
process_with_llm <- function(state, chat) {
response <- chat$submit(state$last_input)
state$results <- c(state$results, list(response))
state$history <- c(state$history, list(
list(type = "llm_call", response = response, timestamp = Sys.time())
))
state
}
# R6 shell
ClinicalAgent <- R6::R6Class("ClinicalAgent",
public = list(
state = NULL,
chat = NULL,
initialize = function(api_key) {
self$chat <- chat_openai(api_key = api_key)
self$state <- list(history = list(), results = list())
},
analyze = function(input) {
self$state$last_input <- input
self$state <- process_with_llm(self$state, self$chat)
return(self$state$results[[length(self$state$results)]])
},
export_audit_trail = function() {
writeLines(jsonlite::toJSON(self$state$history, pretty = TRUE),
"audit_trail.json")
}
)
)
# Usage
agent <- ClinicalAgent$new(api_key = "xxx")
result <- agent$analyze("Summarize adverse events for Study 123")
agent$export_audit_trail() # FDA-ready documentation
That’s a production-ready agent with a complete audit trail. No magic. No black boxes.
The Bigger Picture
The AI agent space is maturing. Early adopters cared about speed. “Ship fast, break things.”
But as AI moves into regulated industries — healthcare, finance, legal — the conversation is shifting. Now it’s about:
- Explainability — Why did the agent make that decision?
- Auditability — Can we prove what happened?
- Reproducibility — Can we run it again and get the same result?
Those aren’t Python’s strengths (out of the box, but they are made available by agent harness today). They’re R’s. The hybrid pattern bridges the gap. You get Python’s ease of use (via R6 interface) and R’s auditability (via functional core).
The Optimization Layer (Langchain blogs are always insightful!)
Here’s where most hybrid architectures fail: they stop at the audit trail.
LangChain team went from Top 30 to Top 5 on Terminal Bench 2.0 by treating the harness as an optimization problem, not just a structure. They added three critical layers:
1. Loop Protection (Middleware Hook)
Agents get stuck. They repeat the same action, burn tokens, and go nowhere. The fix? Detect loops before they happen.
# Middleware hook: check for infinite loops
check_loop <- function(state, current_action, threshold = 3) {
recent_actions <- tail(state$history, threshold)
action_sequence <- sapply(recent_actions, function(x) x$action)
if (all(action_sequence == current_action)) {
# Loop detected! Force a different approach
return(list(
status = "loop_detected",
suggestion = "Try a different tool or strategy",
actions_taken = threshold
))
}
state
}
# Usage in agent loop
agent_loop <- function(input, state) {
state <- add_message(state, input)
for (action in planned_actions) {
loop_check <- check_loop(state, action$action)
if (!is.null(loop_check$status)) {
state <- add_error(state, "Loop detected", loop_check)
break
}
state <- execute_action(state, action)
}
state
}
Result: No more 500-token spirals where the agent calls the same tool over and over.
2. Trace Analysis (Functional Core)
Viv’s insight: traces are the signal. Instead of manually reading logs, analyze them systematically.
# Pure function: analyze failure modes from traces
analyze_traces <- function(traces) {
traces |>
purrr::map_dfr(~tibble(
error_type = .x$error$category %||% "success",
frequency = 1,
timestamp = .x$timestamp,
task_id = .x$metadata$task_id
)) |>
dplyr::group_by(error_type) |>
dplyr::summarise(
count = sum(frequency),
pct = count / sum(count) * 100,
avg_tokens = mean(.x$metadata$tokens, na.rm = TRUE)
) |>
dplyr::arrange(desc(count))
}
# Returns actionable insights:
# # A tibble: 4 × 4
# error_type count pct avg_tokens
# <chr> <int> <dbl> <dbl>
# 1 infinite_loop 23 45.2 1240
# 2 tool_misuse 12 23.5 890
# 3 context_overflow 8 15.7 2100
# 4 success 81 15.9 450
The pattern: Turn traces into data → aggregate failure modes → make targeted harness changes.
3. Adaptive Reasoning (Dynamic Prompt Injection)
Not all tasks need the same reasoning depth. Viv’s team adjusted reasoning levels based on task complexity.
# Dynamic reasoning level selection
get_reasoning_level <- function(task, history = NULL) {
# Base complexity on task length and structure
word_count <- length(strsplit(task, "\\s+")[[1]])
has_questions <- grepl("\\?", task)
base_score <- word_count + (has_questions * 10)
# Adjust based on history (if previous attempts failed)
if (!is.null(history)) {
failures <- sum(sapply(history, function(x) x$status == "error"))
base_score <- base_score + (failures * 15)
}
# Map to reasoning levels
case_when(
base_score > 50 ~ "xhigh", # Complex planning needed
base_score > 20 ~ "high", # Moderate reasoning
base_score > 10 ~ "medium", # Simple tasks
TRUE ~ "low" # Trivial
)
}
# Usage: inject into system prompt
build_system_prompt <- function(task, state) {
reasoning_level <- get_reasoning_level(task, state$history)
sprintf(
"You are a clinical data analyst. Use %s reasoning mode.\n\nTask: %s",
reasoning_level,
task
)
}
Impact: 30% token savings on simple tasks, 15% performance boost on complex ones.
4. Build-Verify Loop Focus
The biggest gain came from explicitly telling the agent to follow a build-verify cycle.
# Enforce build-verify pattern in functional core
build_verify_loop <- function(state, task) {
state <- state |>
add_message(task, timestamp = Sys.time()) |>
plan_step(type = "build_verify", timestamp = Sys.time()) |>
execute_tools(
tools = list(
list(name = "write_code", args = task),
list(name = "run_tests", args = list()),
list(name = "analyze_failures", args = list())
),
timestamp = Sys.time()
) |>
add_audit_metadata(
principle = "Contemporaneous",
timestamp = Sys.time(),
user = Sys.info()[["user"]]
)
# Check if tests passed
if (state$metadata$test_result == "fail") {
# Iterate: analyze failure, adjust code, retry
state <- state |>
add_message("Tests failed. Analyzing...", timestamp = Sys.time()) |>
execute_tools(list(name = "analyze_failures")) |>
execute_tools(list(name = "write_code", args = state$fix_plan))
}
state
}
Why it works: Without this, agents wander. With it, they follow a proven pattern: write → test → iterate.
Putting It All Together
The full hybrid architecture now has three layers:
- R6 Shell — Interface (run, audit, export)
- Functional Core — State transformations (add_message, plan_step, execute_tools)
- Middleware Hooks — Optimization (loop protection, trace analysis, adaptive reasoning)
# Complete hybrid agent with optimization
ClinicalAgent <- R6::R6Class("ClinicalAgent",
public = list(
state = NULL,
chat = NULL,
initialize = function(api_key) {
self$chat <- chat_openai(api_key = api_key)
self$state <- list(
history = list(),
results = list(),
metadata = list(
created = Sys.time(),
loop_threshold = 3,
reasoning_mode = "adaptive"
)
)
},
analyze = function(task) {
# 1. Check for loops (middleware)
loop_check <- check_loop(self$state, task)
if (!is.null(loop_check$status)) {
return(list(error = "Loop detected", suggestion = loop_check$suggestion))
}
# 2. Adaptive reasoning (middleware)
reasoning_level <- get_reasoning_level(task, self$state$history)
# 3. Build-verify loop (functional core)
self$state <- build_verify_loop(self$state, task)
# 4. Return result
return(self$state$results[[length(self$state$results)]])
},
export_audit_trail = function() {
# Full trace for FDA submission
writeLines(
jsonlite::toJSON(self$state$history, pretty = TRUE, auto_unbox = TRUE),
"audit_trail.json"
)
}
)
)
# Usage
agent <- ClinicalAgent$new(api_key = "xxx")
result <- agent$analyze("Analyze adverse events for Study 123")
agent$export_audit_trail() # FDA-ready documentation with optimization metadata
The result? An agent that’s not just auditable—it’s improvable. You can see where it fails, why it fails, and systematically fix the harness.
The Trade-Off (There’s Always One)
Nothing’s free. Here’s what you give up with the hybrid approach:
- Complexity: You’re maintaining three layers now. R6 + functional + middleware hooks. More code to test.
- Performance: Slight overhead from state copying (immutability has a cost) and loop checks on every action.
- Learning curve: Your team needs to understand OOP, functional patterns, and optimization loops.
But here’s the counterpoint:
- Regulatory risk: If you’re in pharma, the cost of non-compliance is way higher than the cost of extra code.
- Reproducibility: When you need to reproduce an analysis six months later (because the FDA asked), the functional core makes that trivial.
- Improvement velocity: With trace analysis, you’re not guessing why the agent failed—you know. That’s how you go from Top 30 to Top 5.
- Maintainability: Pure functions are easier to test than hidden state mutations. Middleware hooks are isolated concerns.
The trade-off makes sense when your use case demands it.
What’s Next?
I’m still exploring this space. Here’s what I’m researching on:
- Multi-agent patterns — How do you do this with multiple collaborating agents?
- Tool registration — Automatic schema generation from function signatures
- State serialization — Saving/loading agent state for long-running workflows
- Testing strategies — How to test functional agent code with middleware hooks
If you’re building agents in R, I’d love to hear what you’re working on. Drop a comment or hit me up on Twitter.
Leave a comment