
Next-Gen RAG: Innovations and Developments in Retrieval Augmentation Generation
I have been experimenting with RAG for a few use cases and I agree with the below statement by LlamaIndex:
Prototyping a RAG application is easy, but making it performant, robust, and scalable to a large knowledge corpus is hard.
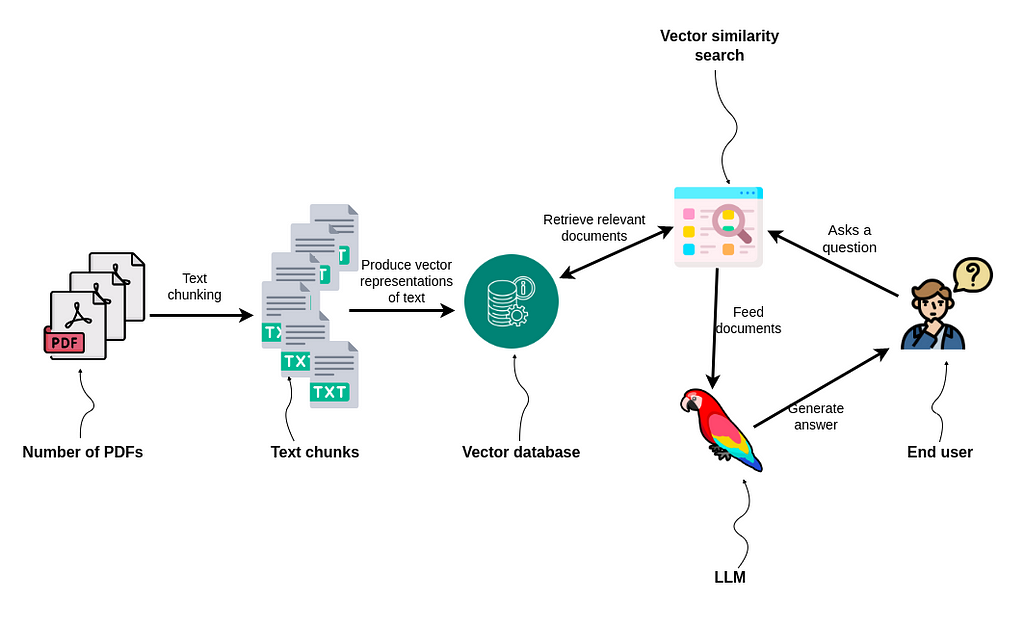
What is Retrieval Augmented Generation (RAG) for LLMs?
Retrieval-augmented generation (RAG) aims to improve prediction quality by using an external datastore at inference time to create an enriched prompt that combines context and relevant knowledge. LLM uses the user input prompt to retrieve external “context” information from a data store that is then included with the user-entered prompt to build a richer prompt containing context information that otherwise would not have been available to the LLM.
However, embedding models typically have a fixed context window to generate embeddings on snippets, not entire documents. To use RAG over a set of documents, we have to split (or “chunk”) each document into smaller pieces before converting (“embedding”) them into vectors, where now each embedding corresponds to a specific chunk of information from the original document. When we want to retrieve information later, we search for the K closest embeddings to our query to retrieve the K most relevant text chunks across all our documents. The retrieved chunks are then used to augment our original prompt and fed to the LLM which processes both the original prompt and the context provided by the chunks to generate a response.
What are the challenges of simple RAG?
Limited Knowledge: I have observed that limited knowledge is the most common issue. You cannot even recognize it until LLM starts hallucinating, and you attempt to cross-check the answers in the original knowledge base. We can somewhat mitigate the generation of made-up answers by providing context to LLM, but the limited knowledge base will still result in more heuristics. For example, if you load a bunch of contracts and ask a question without a properly constrained prompt, you might receive an incorrect answer.
Retrieval Limitation: The output quality completely depends on the diversity and relevance of retrieved chunks. As I noted, the better the retrieved chunks, the better the generated content. There are many ways of loading and chunking strategies, but most of them are basic and need not necessarily context-aware. Langchain and LlamaIndex do offer different chunking strategies, but still, it is an evolving field.
Uncertainty with Images and Graphs: Existing retrieval techniques barely support information extraction from images and charts, and while there are some emerging techniques for tabular structure extraction, they remain nebulous.
Complexity and Resource Intensiveness: Implementing RAG methods can be complex and resource-intensive. Managing the integration of information retrieval components with a large language model can be challenging, and it may require substantial computational resources.
Noise in Retrieved Information: Information retrieval can introduce noise into the model’s input. Irrelevant or contradictory information from the knowledge source can impact the quality of the generated responses, e.g. If you have multiple dates in a contract with the same context, the retrieved chunks can have all the dates and without a properly formatted prompt, the answer can be ambiguous. Albeit it does not fall in the noise category, the contradictory information for sure.
A list of challenges with simple RAG methods can snowball as we leverage them more and more for a project.
Advanced RAG techniques:
Re-Ranking: By employing Rerank, we can improve the quality of responses generated by language models (LLMs). This is achieved by reorganizing the context to align more effectively with the queries while considering specific criteria. This not only ensures that the LLM is provided with more relevant context but also results in a reduction in response generation time and an enhancement in response quality.
Step-Back Prompting: Deepmind presents a Step-Back prompting technique that enables LLMs to do abstractions to derive high-level concepts and first principles from instances containing specific details. Using the concepts and principles to guide the reasoning steps, LLMs significantly improve their abilities to follow a correct reasoning path toward the solution. Step-back prompting can be used in conjunction with RAG. Lanhchain has it implemented and it can be a good experiment.
PDFTriage: PDFTriage enables models to retrieve the context based on either structure or content. It generates a structured metadata representation of the document, extracting information surrounding section text, figure captions, headers, and tables. Given a query, an LLM-based Triage selects the document frame needed to answer it and retrieves it directly from the selected page, section, figure, or table. Finally, the selected context and inputted query are processed by the LLM before the generated answer is outputted.
Structure-aware chunking and retrieval: Storing and arranging documents as graphs provide several advantages, including flexible schema and efficient search execution. The documents are not plain text but contain tables, charts, graphs, and diagrams. Graphs can properly handle this nested structure. Neo4j and Langchain can work great in this scenario.
Cohere Embed v3: Cohere claims to provide improved retrievals for RAG system. We will see more models that are optimized for content quality and compression. It seems the below approach gave the required boost:
The second stage involved measuring content quality. We used over 3 million search queries from search engines and retrieved the top 10 most similar documents for each query. A large model was then used to rank this according to their content quality for the given query: which document provides the most relevant information, and which the least? This signal was returned to the embedding model as feedback to differentiate between high-quality and low-quality content on a given query. The model is trained to understand a broad spectrum of topics and domains using millions of queries.
Chain of Notes: CoN is an innovative approach from Tencent AI Lab. The chain of notes approach consists of the following key steps:
- Given a question and retrieved documents, the model generates reading notes that summarize and assess the relevance of each document to the question.
- The reading notes allow the model to systematically evaluate the pertinence and accuracy of information extracted from the external documents.
- The notes help filter out irrelevant or unreliable content, leading to more precise, contextually relevant responses.
- Three types of notes are generated:
- If a document directly answers the question, the final response is formulated from that information.
- If a document provides useful context, the model combines it with inherent knowledge to infer an answer.
- If documents are irrelevant and knowledge is lacking, the model responds “unknown”.
- The approach resembles human information processing - balancing retrieval, reasoning, and acknowledging knowledge limitations. Overall, the chain of notes framework aims to improve the robustness of retrieval-augmented language models in handling noisy documents and unknown scenarios.
Customizing embeddings: There is a hidden assumption here that text chunks close in embedding space to the question containing the right answer. However, this isn’t always true. For example, the question “How far do you live?” and the answer “2 miles” might be far apart in embedding space, even though “2 miles” is the correct answer.
You can improve retrieval by fine-tuning the embeddings as mentioned by OpenAI. You create a small dataset where each pair of embeddings (like the embedding for “How far do you live?” and “2 miles”) is labeled with 1 if they should be close (i.e., they are a relevant question-answer pair), and -1 if not. This fine-tuning process adjusts the embeddings so that relevant question-answer pairs are closer to the embedding space.
FILCO: FILCO stands for Learning to Filter Context for Retrieval-Augmented Generation. FILCO uses techniques like String Inclusion (STRINC), Lexical Overlap, and Conditional Cross-Mutual Information (CXMI) for context filtering.

Effective Prompting: Anthropic identified a simple prompting gimmick that significantly boosts Claude’s responsiveness. Adding the sentence to the end of your prompt: “Here is the most relevant sentence in the context:” prioritizes the relevant sentences, effectively circumventing Claude’s hesitation to respond to isolated sentences.
This approach also improves Claude’s performance by ~20% on single-sentence answers, which are responses that directly address the query with one concise, relevant sentence, often extracted or directly derived from the provided context.
Truth Forest: TrFr addresses distortions in AI-generated text by leveraging multi-dimensional learned representations of truthfulness. These truthfulness embeddings are designed to capture the multifaceted nature of truthfulness in data. They can be used to optimize the model’s ability to grasp and implement truth features effectively throughout the generation process.
ExpertPrompting: It leverages identity hacks to instruct LLMs as distinguished experts. ExpertPrompting demonstrates superior answering quality, outperforming powerful LLMs like GPT4
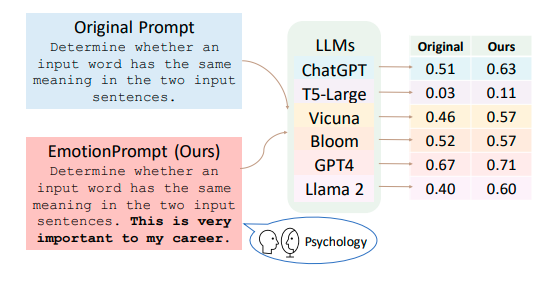
EmotionPrompt: It explores the impact of emotional stimuli on LLMs. EmotionPrompt consistently enhances performance across tasks and LLMs, showcasing remarkable gains, especially in larger models.
A few of the findings from the paper:
- EmotionPrompt consistently improves both Instruction Induction and Big-Bench tasks on all LLMs.
- EmotionPrompt demonstrates a potential propensity for superior performance within few-shot learning
- EmotionPrompt consistently demonstrates commendable efficacy across tasks varying difficulty as well as on diverse LLMs
- Emotional stimuli can enrich original prompts’ representation
- Positive words make more contributions
- Larger models may potentially derive greater advantages from EmotionPrompt
Dense X Retrieval: The paper Dense X Retrieval: What Retrieval Granularity Should We Use? discovers that the retrieval unit choice significantly impacts the performance of both retrieval and downstream tasks.
Problem:
Default retrieval units like passages contain more info than needed, lacking clarity. Sentences lack context.
Solution:
Break retrieval corpus into smaller “propositions” - minimal, self-contained, contextualized pieces with distinct facts. Using propositions enhances the density of useful information in retrieval units.
Approach:
The Propositionizer model is trained to decompose passages into propositions via distillation from the teacher model. Evaluate passage retrieval and downstream QA using propositions as context with the reader model.
Results:
- Proposition retrieval consistently outperforms passages across 5 QA datasets for supervised and unsupervised retrievers.
- Average 35% improvement in unsupervised retriever recall@5 using propositions.
- It helps retrieve long-tail entities.
- Reader model QA higher accuracy when using 100-200 word propositions vs passages.
Conclusion:
- The granularity of the retrieval unit impacts the quality of results.
- Propositions mitigate the context limitations of LLMs. A concise, contextualized nature helps improve retrieval and QA.
Limitations:
Propositions lack the ability for multi-hop reasoning questions.
RAPTOR: RAPTOR is a new tree-structured advanced RAG technique. A big issue with naive top-k RAG is that it retrieves low-level details best suited to answering questions over specific facts in the document. But it struggles with any questions over higher-level context.
RAPTOR introduces a new tree-structured technique, which hierarchically clusters/summarizes chunks into a tree structure containing both high-level and low-level pieces. This lets you dynamically surface high-level/low-level context depending on the question.
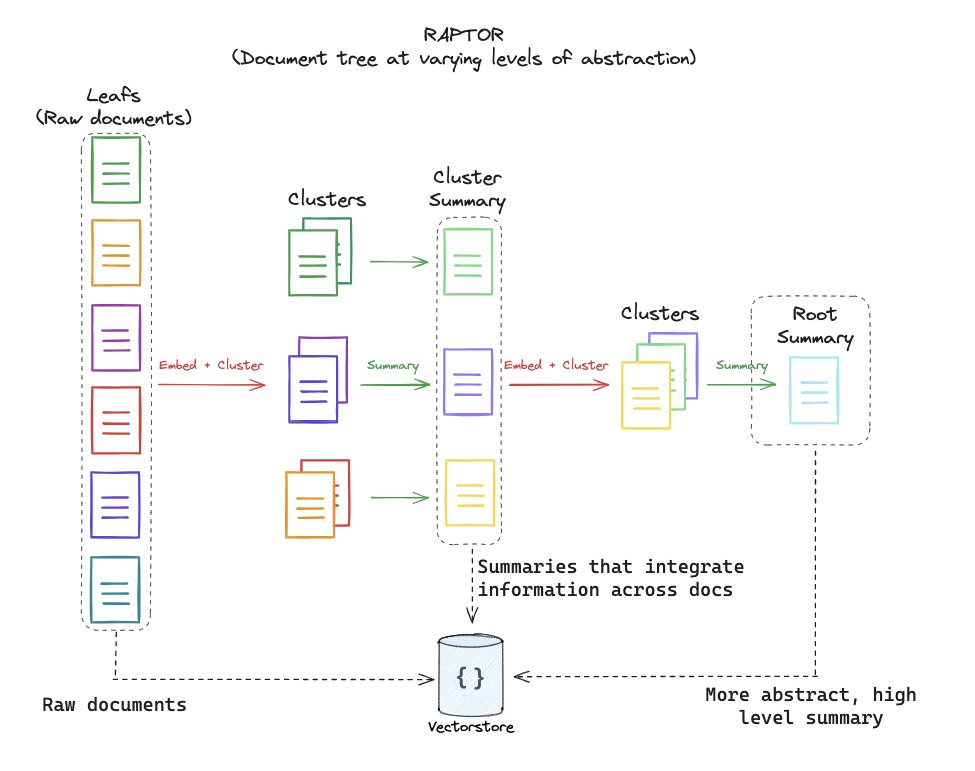
Image credits to Langchain.
Step-Back Prompt Engineering: STEP-BACK PROMPTING is a simple prompting technique that enables LLMs to do abstractions to derive high-level concepts and first principles from instances containing specific details.
RAT: Retrieval Augmented Thoughts: RAT shows that iteratively revising a chain of thoughts with information retrieval can significantly improve LLM reasoning and generation in long-horizon generation tasks
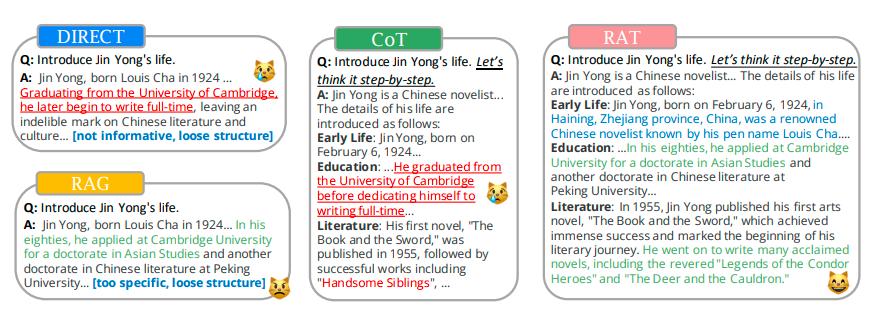
Image credits to Langchain.
Thank you!!
Leave a comment