

Prompt Engineering for Named Entity Recognition
Hi All,
Prompt engineering refers to the strategic design of crafting a starting text in natural language processing (NLP) tasks to guide models toward desired behavior. The input prompt plays a crucial role in shaping the output generated by the model. The goal is to influence the model’s behavior, improve performance, or achieve specific outcomes.
Why LLM can be a good option for entity extraction out of the box?
Contextual Understanding:
Large language models capture contextual relationships between words in a text. This contextual understanding is crucial for entity extraction, where the presence and boundaries of entities often depend on the surrounding words and context. This is essential for accurate identification of entities in a sentence.
Semantic Representations:
Large language models generate high-dimensional semantic representations of words, which encode not only their syntactic but also semantic relationships. This is beneficial for distinguishing between entities and other words based on their meaning within a given context.
Flexibility Across Domains:
Large language models pre-trained on diverse datasets can handle a wide range of domains and topics. This flexibility is advantageous for entity extraction tasks in different domains without the need for extensive task-specific pre-training. We can even better results from domain-specific models
Parameter Tuning and Model Size:
LLMs with more parameters can capture intricate patterns in the data. Fine-tuning a large model on a specific entity extraction task often leads to better performance compared to smaller models.
What are the prompting techniques we have at our disposal:
- Zero-shot prompting
- Few-shot prompting
Zero-shot Prompting:
Zero-shot prompting is the method of using natural language prompts to guide pre-trained LLMs on downstream tasks without any gradient updates, fine-tuning of the model, or providing any sample input-output example.

Our observations with the zero-shot prompting technique for NER:
- LLMs find it challenging to generalize based solely on context. We have observed that the attribute sequence is neither constant nor reproducible. Additionally, the constraints are loose.
- As context length increases, the output reproducibility becomes increasingly difficult.
- LLM does not understand/follow the hard constraints every time.
Few-shot Prompting:
Few-shot prompting is a technique that leverages the capabilities of Large Language Models (LLMs) to perform specific tasks. By providing a few examples, known as “shots,” the model can be conditioned to generate desired outputs, such as text, code, or images.
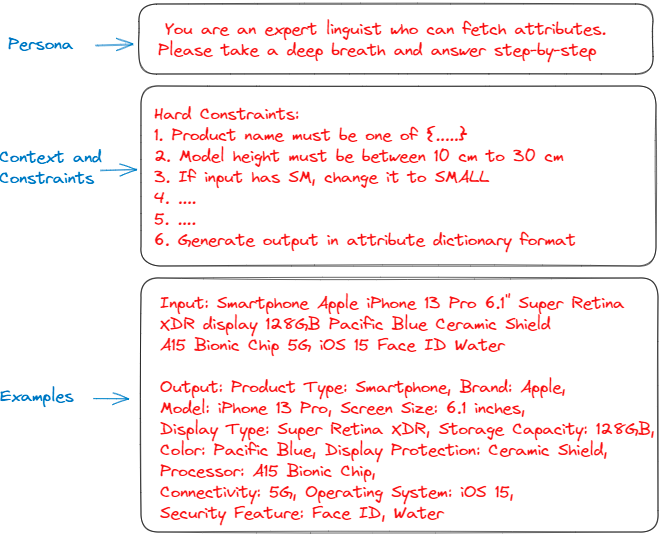
Our observations with the few-shot prompting technique for NER:
- A few diverse examples help LLM to learn the attribute sequence.
- The more examples (shots), the better.
- Diversity in examples plays an important role.
- The attribute sequence in all examples needs to be the same and it is critical for the result reproducibility.
Relevant Few-shot Prompting:
In the course of our exploration into few-shot prompting, a prominent challenge has emerged, primarily stemming from the constrained number of examples available within a given context. This limitation poses a restriction on the diversity of examples at our disposal. The static nature of examples incorporated into prompts introduces a potential drawback – their efficacy is not universal across all input descriptions. While these examples demonstrate optimal performance when the input descriptions closely align with or bear similarity to the prompt examples in context, their effectiveness diminishes when confronted with inputs characterized by distinct prompt examples. In essence, the adaptability of static examples within prompts is contingent on the contextual proximity between the provided examples and the input descriptions.
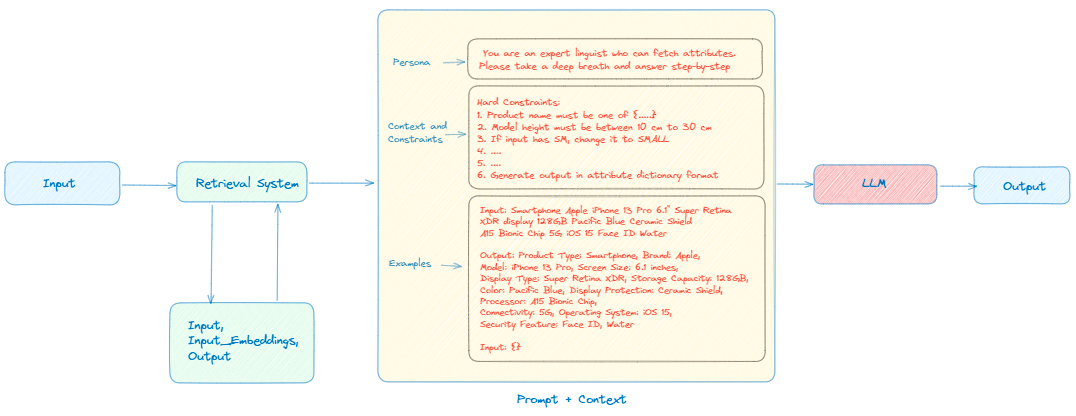
An optimal approach involves incorporating dynamic examples encapsulated within prompts that closely align with input descriptions. This can be achieved through the implementation of grounded training data. By establishing a vector database (vectorDB) akin to AlloyDB, utilizing technologies such as PostgreSQL in conjunction with pgvector for hosting {Input, Output, Input Embeddings} tuples, we create a platform for efficient retrieval.
When a new input is introduced, it undergoes a conversion into embeddings, facilitating a similarity search within vectorDB. This search involves comparing the input embeddings to those stored in the database. The top-k most similar {input + Output} examples are subsequently extracted and integrated into the prompt context as few-shot examples.
The modified context, enriched with relevant examples closely mirroring the input, is then presented to the Language Model (LLM) along with the original input, as illustrated in the accompanying diagram. This innovative approach is anticipated to yield superior results in comparison to the conventional static few-shot prompting method.
Stay tuned for more in-depth articles in collaboration with Vikrant Singh. You can also visit his medium articles
Thank you!!


Leave a comment