
Open Source options to your MLOps stack.
Hey All,
First blog of 2022! 💪
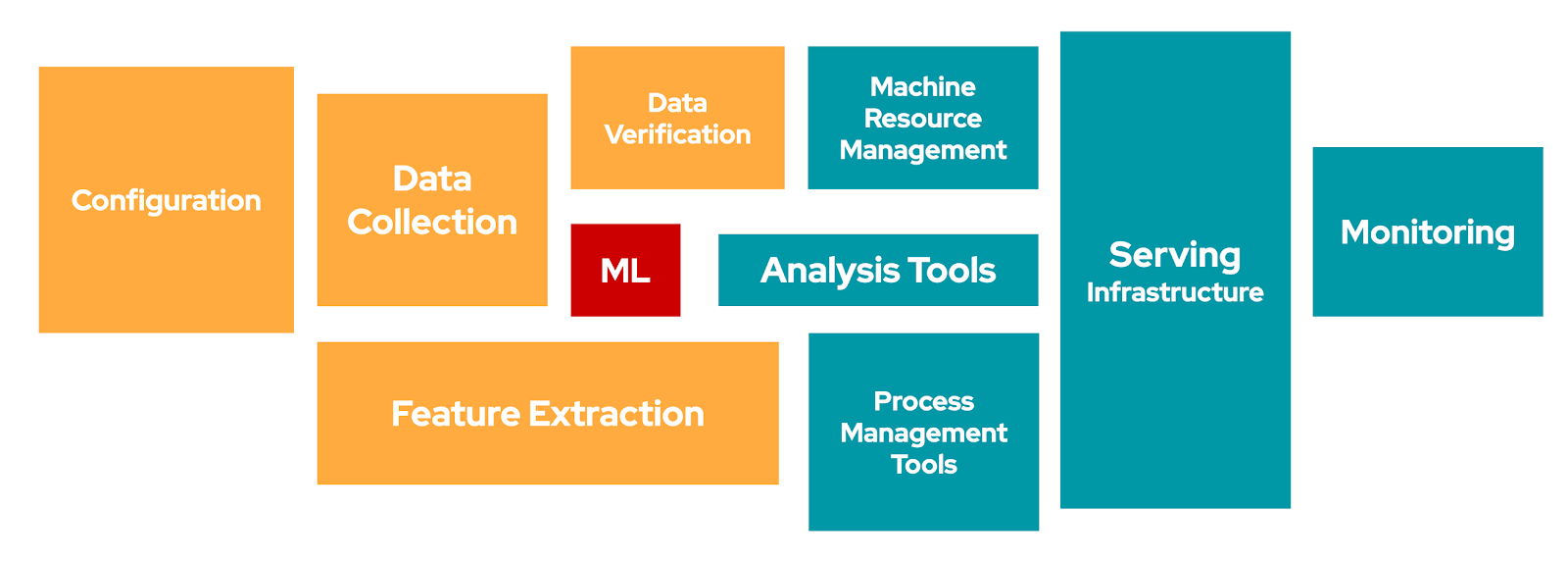
Let me put the latest web search trend of MLOps. It has been picking up in recent years. Any guesses which country is leading the march? CHINA! We have been witnessing MLOps explosive in the US, but unware of China. Let’s try to see what are the open-source building blocks we have and how can we leverage them to build a reliable data & ML stack. We have multiple options at each stage, but we will keep it open-source-focused.
Data Stack
The purpose of the data stack is to source data from an external system, load it in a warehouse/lakehouse, and massage it for the next journey. It can work in either of these fashions: ETL or ELT. Many companies are moving to ELT (Extract, Load, and Transform) paradigm for multiple reasons.
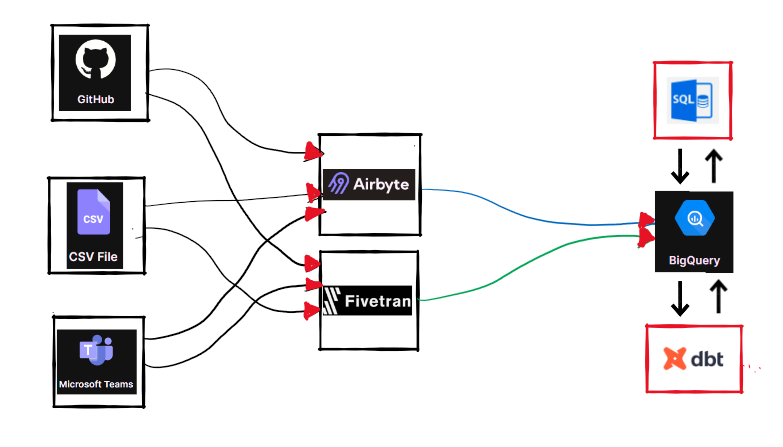
I was researching the modern data stack and came across Airbyte, an open-source data integration solution. It eases data integration and is getting traction in the industry. I created below data stack which we mostly come across while working on small to mid-size projects. Fivetran is an alternative, but it is closed-source. We can create connections in Airbyte/Fivetran for the required data sources and assign the target location (mostly datalake/datawarehouse). I have referred BQ as an option. We can schedule the data load pipeline through Airflow or Prefect. I have previous blog posts on Prefect for reference. I found it easy to use and schedule. Once we have data stored in BQ, the data analysis can be performed using simple SQL or dbt (SQL + Versioning).
We can take advantage of dbt + Airflow + Great Expectations trio. Great Expectations is an open-source data quality solution. I found it very helpful both for personal and professional work. I tried TFDV and Great Expectations for data validation and data quality checks in my MLOps pipeline on GCP. I am looking after using deepchecks for upcoming projects. We can deploy this Airflow DAG on Cloud Composer.
Now we have options such as Looker, Superset, and a recent addition of Lightdash for exploratory analysis. We can use Tableau and/or Power BI as well. A lot of options out there! I use Data Studio and Power BI for most of my work.
ML Stack
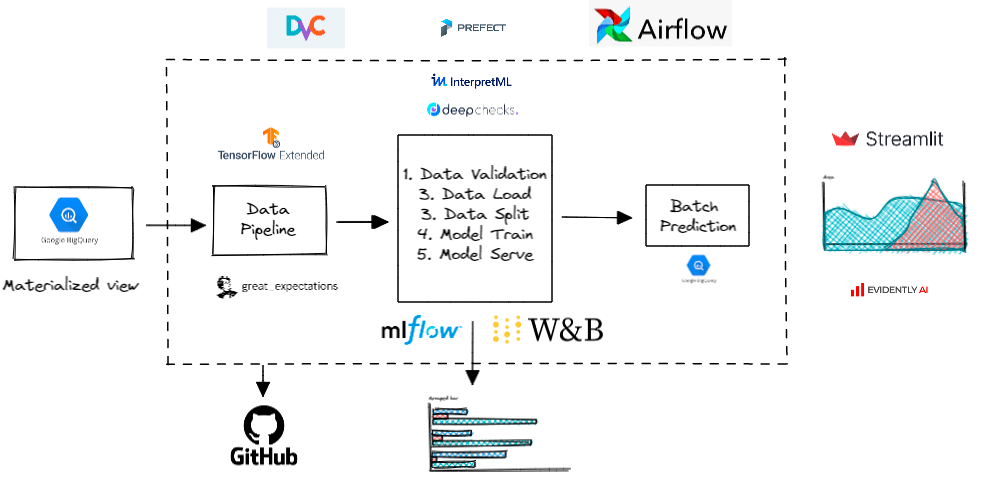
Let’s assume we have structured data in Google BQ. We have multiple options to optimize the data storage in BQ based on the applications. The materialized views are worth exploring for increased performance and efficiency. As per Google, “Queries that use materialized views are generally faster and consume fewer resources than queries that retrieve the same data only from the base table. Materialized views can significantly improve the performance of workloads that have the characteristic of common and repeated queries.”
When it comes to data validation, it is an integral part of MLOps and can be added at multiple milestones. We have many promising options to choose. Great Expectations is one of such options. We can start using it in the Jupyter notebook and eventually make it a standard option in MLOps. It has a great option of creating an Expectation Suites to validate the new data along with Data Docs. It can also be seamlessly integrated into workflow orchestration frameworks such as Airflow and Prefect. TFDV is also a useful alternative for descriptive statistics and schema reinforcement. I found GE easy to use and share.
Next comes Experimentation and scripting. We, Data Scientists, spend most of our time in this space. Once our data validation pipeline runs successfully, we have quality data at our disposal. We need to load the data from BLOB storage (most of the time) to JupyterLab for EDA purposes. I have written an article about DS project structure. We start with Jupyter notebooks for exploration and experimentation, design modular scripts for each part of the development phase, write unit tests, make config files, add MLFlow or Wandb for experiment tracking and logging. There are many best practices out there that companies are leveraging to standardize the ML process. We have emerging tools such as InterpretML and deepchecks to test in the ML pipelines. I would recommend referring Made with ML for an applied ML production-grade content. I personally learned a lot going through madewithml.com. DVC can be a good option for tracking data files alongside Github.
When we run the final scripts using DVC/Airflow/Prefect in the Dev/Prod environment, the batch predictions can be persisted as a table in the database. I have used the BQ table to save the batch predictions. We can also persist the model pipelines and keep track of the best-performing models. We have a couple of examples for the model monitoring like Vertex AI Monitoring, Evidently AI. Evidently AI can be used to run data and model checks as a part of MLFlow/Airflow pipeline. It also generates sharable reports for debugging. If we are generating any report such as CSV/Excel as an output, it should be pushed to the storage bucket. The model artifacts can be pushed to GCS bucket for versioning and automation purpose.
When it comes to online inference, we have a bunch of tools for quick prototyping. Streamlit is easy to use and fast to build tool. We do have FastAPI, high-performance web framework as a great alternative. FastAPI has a couple of advantages over Flask tool. FastAPI is faster thanks to ASGI, automatic docs, type declarations (for validation) !! I will keep appending the list as I come across new tools.
Explore while working on project:
- requirements.in + pip-compile -> requirements.txt
Thank you..


Leave a comment