

Prefect - Workflows for Data Science Projects!
Hi All,
Prefect is a new workflow management system, designed for modern infrastructure and powered by the open-source Prefect Core workflow engine. The team claims that they rebuilt data engineering for the data science era. I was looking for easy to learn, quick-to-set-up, data scientist-friendly tool. I explored Airflow, but found it difficult to learn quickly. No doubt Airflow is a great workflow management platform, but the setup is time-consuming. I also tried Metaflow, an open-sourced framework for real-life data science, but could not run successfully on windows OS. Finally, Prefect came to the rescue and fitted perfectly in my MLOps toolkit.
from prefect import Flow, task
from typing import List, Dict, Any
import prefect
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score,recall_score,accuracy_score,precision_score,confusion_matrix,classification_report
@task
def load_data(external_path: str,
raw_data_path: str,
model_var: List[str]):
data = pd.read_csv(external_path,
sep=',',
encoding='utf-8')
data = data[model_var]
data.to_csv(raw_data_path, index=False)
return None
@task(nout=2)
def split_data(raw_data_path: str,
train_data_path: str,
test_data_path: str,
split_ratio: float,
random_state):
data = pd.read_csv(raw_data_path,
sep=',',
encoding='utf-8')
data_train, data_test = train_test_split(data,
test_size=split_ratio,
random_state=random_state)
data_train.to_csv(train_data_path, index=False)
data_test.to_csv(test_data_path, index=False)
return data_train, data_test
@task(nout=2)
def get_feat_and_target(df: pd.DataFrame, target: str):
"""
Get features and target variables seperately from given dataframe and target
input: dataframe and target column
output: two dataframes for x and y
"""
x=df.drop(target,axis=1)
y=df[[target]]
return x,y
@task
def train_model(X_train, y_train,
X_test, y_test,
model_type,
max_depth, n_estimators):
if model_type == "random_forest":
model = RandomForestClassifier(max_depth=max_depth,
n_estimators=n_estimators)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
return y_pred
@task(nout=4)
def accuracymeasures(y_test,predictions,avg_method):
accuracy = accuracy_score(y_test, predictions)
precision = precision_score(y_test, predictions, average=avg_method)
recall = recall_score(y_test, predictions, average=avg_method)
f1score = f1_score(y_test, predictions, average=avg_method)
target_names = ['0','1']
print("Classification report")
print("---------------------","\n")
print(classification_report(y_test, predictions,target_names=target_names),"\n")
print("Confusion Matrix")
print("---------------------","\n")
print(confusion_matrix(y_test, predictions),"\n")
print("Accuracy Measures")
print("---------------------","\n")
print("Accuracy: ", accuracy)
print("Precision: ", precision)
print("Recall: ", recall)
print("F1 Score: ", f1score)
return accuracy,precision,recall,f1score
with Flow("Prefect_MLOps") as flow:
external_path = 'data/external/train.csv'
raw_data_path = 'data/raw/train.csv'
model_var = ['churn','number_vmail_messages','total_day_calls','total_eve_minutes','total_eve_charge','total_intl_minutes','number_customer_service_calls']
target = 'churn'
train_data_path = 'data/processed/train.csv'
test_data_path = 'data/processed/test.csv'
split_ratio = 0.3
random_state = 42
max_depth = 10
n_estimators = 100
load_data(external_path, raw_data_path, model_var)
data_train, data_test = split_data(raw_data_path,train_data_path, test_data_path, split_ratio, random_state)
x_train, y_train = get_feat_and_target(data_train, target)
x_test, y_test = get_feat_and_target(data_test, target)
y_pred = train_model(x_train, y_train,
x_test, y_test,
"random_forest",
max_depth, n_estimators)
accuracy,precision,recall,f1score = accuracymeasures(y_test, y_pred, 'weighted')
#flow.run()
flow.register(project_name="MLOps_run")
The steps are straightforward to run prefect flow:
> prefect create project MLOps_run
> python script.py
> prefect agent local start
Once we run the flow and start the local agent, the flow gets registered at prefect cloud. We have logs and a schematic available for the flow. It shows the dependencies and data flow overview.
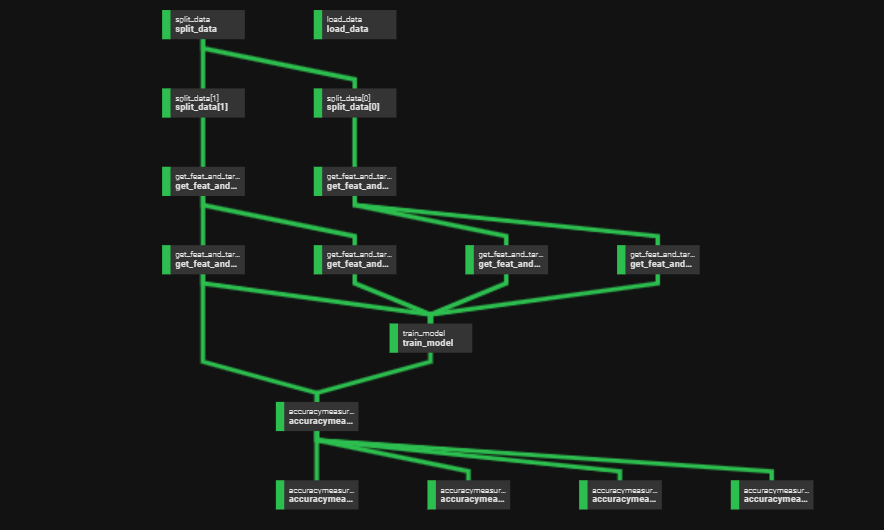
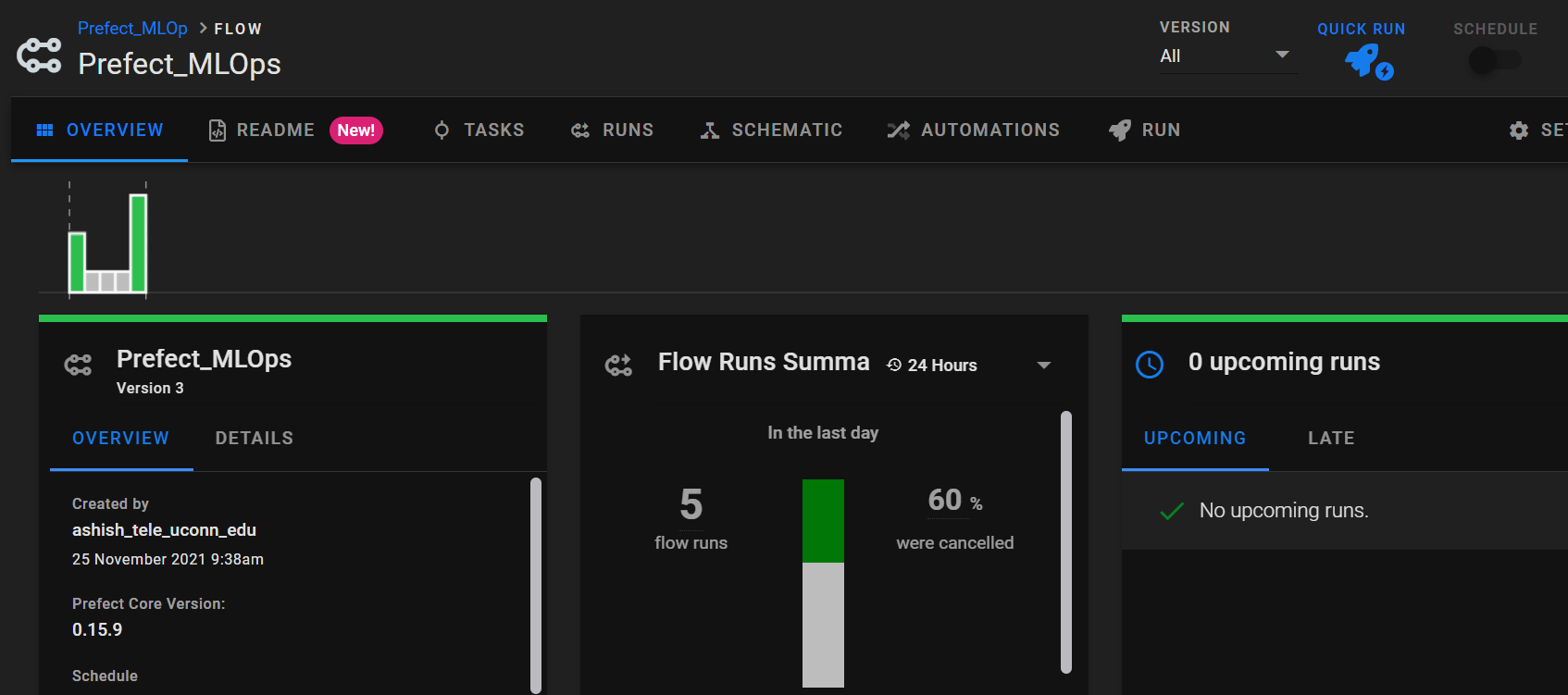
The overview page looks like as shown below. We can run each flow manually by clicking ‘run’. There are options to schedule the runs for specific times, provided we have an active agent. An automation option is a great way to create flow dependency,e.g., when flow does this, then do this.


Leave a comment