
Exploring the Power of Large Language Models: A Comprehensive List of Resources!
Hi All,
The internet is awash with information about large language models (LLMs). Every day, a plethora of papers are published on LLMs, advancing the state-of-the-art (SOTA) benchmarks. I found it overwhelming to keep up with the research and the rapid pace of development. I am listing a few resources that I found helpful and will keep on adding to this list.
Chain-of-Agents (CoA) is a novel framework that enables large language models (LLMs) to collaboratively tackle long-context tasks by dividing the workload across specialized agents. Unlike traditional methods like RAG (retrieval-augmented generation) or expanding LLM context windows—which risk missing critical information or struggling with focus—CoA employs worker agents to process text segments sequentially and a manager agent to synthesize their insights into a coherent output. This approach allows LLMs to maintain precision by handling shorter contexts while aggregating knowledge across the entire input, addressing the “lost in the middle” problem seen in long-context models. Evaluations on tasks like question answering, summarization, and code completion show CoA outperforming RAG and other multi-agent frameworks by up to 10%, demonstrating its efficiency and scalability without requiring additional training. Combining modular reasoning with collaborative synthesis allows CoA to offer a versatile solution for applications requiring deep, accurate analysis of lengthy documents.
Traditional Retrieval-Augmented Generation (RAG) systems rely on a two-step process: first, semantic search retrieves documents based on surface-level similarities; then, a language model generates answers from those documents. While this method works, it often misses deeper contextual insights and can pull in irrelevant information. ReAG – Reasoning Augmented Generation – offers a robust alternative by feeding raw documents directly to the language model, allowing it to assess and integrate the full context. This unified approach leads to more accurate, nuanced, and context-aware responses.
The best explanation of LLM for non-tech people. This article provides an excellent introduction to the world of large models, making it accessible to beginners. I found it very helpful to understand the self-attention part in layman’s terms.
One of the best visual guides out there for transformers is available in three videos: “Position Embeddings,” “Multi-Head and Self-Attention,” and “Decoder’s Masked Attention.” These videos highlight fundamental concepts.
The blog “The Illustrated Transformer” by Jay Alammar provides a concise and visually appealing explanation of the Transformer model, a basic building block for the current revolution in NLP. It covers the key components and operations of the Transformer, including self-attention and positional encoding, in the best possible way. The blog’s illustrations help clarify the model’s inner workings, making it accessible and informative for readers interested in understanding the Transformer architecture. If you are a visual learner like me, this should be the starting point for you!
AssemblyAI’s blog, “The Full Story of Large Language Models and RLHF,” explores the innovations and advancements in large language models (LLMs) and Reinforcement Learning from Human Feedback (RLHF). The blog delves into the history and development of LLMs, such as GPT-3, and outlines their capabilities and limitations. It highlights the role of RLHF in fine-tuning LLMs and discusses its potential for improving their performance and addressing biases. Additionally, the blog provides insights into cutting-edge techniques used in training and refining LLMs, which showcases the ongoing innovation in the field. Other informative blogs from AssemblyAI:
Sebastian Raschka is known for writing some of the best AI-based blogs. He consistently delivers great content through his blog and more recently through Lightning AI. He provides highly informative content on topics such as Low-Rank Adaptation (LoRA) and Parameter-Efficient Finetuning. The blogs feature pseudocode and visual representations, enhancing the understanding of the concepts.
This learning guides you through a curated collection of content on Generative AI products and technologies, from the fundamentals of Large Language Models to how to create and deploy generative AI solutions on Google Cloud. It is a growing list.
The comprehensive NLP curriculum covers the basics to advanced topics in large language models (LLMs). The curriculum is designed for learners from all backgrounds, with hands-on exercises to help you build and deploy your own models. They cover everything from semantic search, generation, classification, embeddings, and more. Their curriculum is one-size-fits-all, so you can pick your own path based on your previous knowledge and goals.
The Full Stack Deep Learning LLM Bootcamp teaches participants how to build and deploy applications with Large Language Models (LLMs). The bootcamp covers a wide range of topics, including prompt engineering, LLMops, and user experience design. It is open to anyone with an interest in LLMs, regardless of their level of experience with machine learning. The videos are available on YouTube.
Large language models can be used to improve product search by understanding natural language queries and providing more relevant results. This blog post discusses the challenges of traditional search systems and how LLMs can be used to overcome them. It also provides real-world examples of how LLMs are being used to improve product search. LLM: Application through Production is aimed at developers, data scientists, and engineers looking to build LLM-centric applications with the latest and most popular frameworks.
This course focuses on the fundamental principles and concepts of distributed systems. It covers topics such as distributed algorithms, consistency and replication, fault tolerance, and distributed storage. It teaches the fundamentals about the modeling, systems, and ethical aspects of foundation models. It is a great offering from Stanford.
Prompt engineering is the art of writing prompts that get large language models (LLMs) to do what you want them to do. This guide was created by Brex for internal purposes and covers the history of LLMs, as well as strategies, guidelines, and safety recommendations for working with and building programmatic systems on top of LLMs.
Andrej Karpathy delivered the “State of GPT” session for the Microsoft Build 2023 event. He explained the GPT assistant training pipeline, which includes pretraining, supervised fine-tuning (SFT), reward modeling, and reinforcement learning. I particularly liked the recommendations at the end of the video. Great summary thread!
It shows how we can leverage a large language model in combination with our own data to create an interactive application capable of answering questions specific to a particular domain or subject area. The core pattern behind this is the delivery of a question along with a document or document fragment that provides relevant context for answering that question to the model. The model will then respond with an answer that takes into consideration both the question and the context.
a16z has shared a reference architecture for the emerging LLM app stack. It shows the most common systems, tools, and design patterns they have seen used by AI startups and sophisticated tech companies.
This course provides a comprehensive understanding of generative AI, covering key aspects of the LLM-based generative AI lifecycle, from data gathering to deployment. Participants will learn about the transformer architecture behind LLMs, their training process, and the adaptability of fine-tuning to specific use cases. The course also focuses on optimizing the model’s objective function using empirical scaling laws and applying state-of-the-art techniques for training, tuning, and deployment. Participants will gain insights into the challenges and opportunities that generative AI presents for businesses through industry stories shared by researchers and practitioners.
I found this guide useful and practical. I have been experimenting with a few of its suggestions, and it serves as a good starting point that you can build upon and iterate.
A practical guide on how to develop a RAG-based LLM application from scratch, scale, evaluate, and serve the application in a highly scalable manner. A great read from Goku Mohandas.
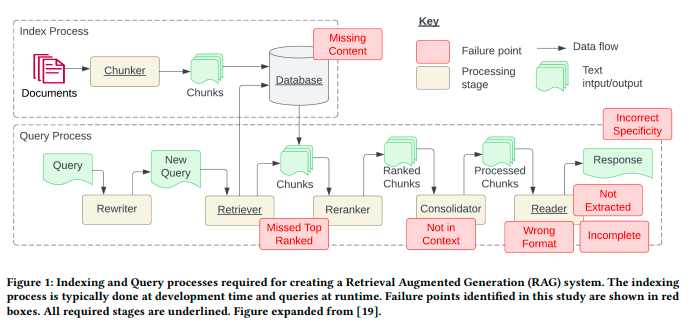
This paper describes 7 most common failure points while implementing RAG system.
The SELF-DISCOVER framework presents a significant advancement in enhancing the performance of language models like GPT-4 and PaLM 2 across demanding reasoning benchmarks such as BigBench-Hard, grounded agent reasoning, and MATH. Its impact is noteworthy, showcasing improvements of up to 32% when compared to the Chain of Thought (CoT) approach.
Moreover, SELF-DISCOVER demonstrates superiority over inference-intensive methodologies like CoT-Self-Consistency by surpassing their performance by over 20%, all while demanding substantially less inference compute, typically in the range of 10-40 times fewer computations.
Additionally, the research illustrates that the reasoning structures self-discovered by this framework exhibit universality across various model families. They seamlessly translate from models like PaLM 2-L to GPT-4 and from GPT-4 to Llama2, displaying similarities with patterns observed in human reasoning processes.

I found this three-part series very useful and practical. It addresses the real-world problems we face when building applications. Part 1 covers the basics and some considerations in system design, key concerns such as question complexity, and the need for new solutions.
Retrieval-Augmented Generation (RAG) systems enhance language models by integrating retrieval mechanisms for more accurate responses, yet the impact of their components and configurations remains understudied, necessitating deeper analysis for optimization. This paper introduces advanced RAG designs, including query expansion, novel retrieval strategies, and Contrastive In-Context Learning, systematically evaluating factors like model size, prompt design, chunk size, and multilingual knowledge bases through experiments. The findings provide actionable insights for balancing contextual richness and efficiency, advancing adaptable RAG frameworks for real-world applications, with code and implementation details made publicly available
Thank you!

Leave a comment