Mistakes to avoid in MLOps!
Hi All,
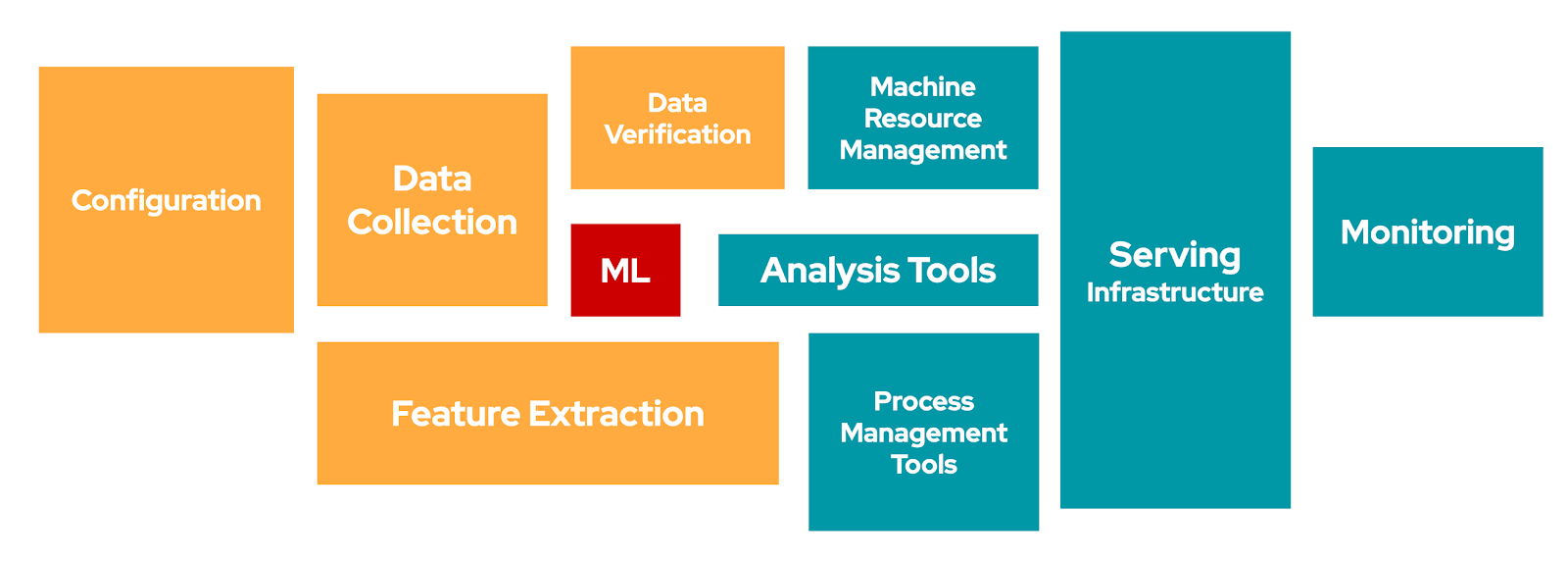
Recently I came across a paper on Arxiv Sanity named Using AntiPatterns to avoid MLOps Mistakes. The authors describe the lessons learned from developing and deploying machine learning models at scale across the enterprise. BNY Mellon presented the learnings in the form of antipatterns. I think the lessons are vital for not only the financial analytics applications but also all the industries.
I found a few points noteworthy to be mentioned. The authors mention “It is imperative that the part of a learning pipeline concerned with hyper-parameter optimization be explicitly and painstakingly documented so as to be reproducible and easily adaptable.” From my experience, MLflow helped me to save the parameters and artifacts to track the model performance and help reproduce the results.
In the financial analytics context, the Authors found the KISS principle helpful. In their words, it encourages developers to try simple models first and conduct an exhaustive comparison of models before advocating for specific methodologies. KISS stands for ‘Keep it simple, stupid. It is a design principle which states that designs should be as simple as possible. I think the KISS principle is valid for almost all the verticals. It may be because of multiple reasons such as complexity, incremental performance improvement, infrastructure limitations, latency and throughput trade-off, etc.
Repeated testing against the known test set, modify their model accordingly to improve performance on the known test set is called HARKing (Hypothesizing After Results are Known). It leads to implicit data leakage. It has potential effects of over-fitting and selection bias in performance evaluation. The acronym HARKing is borrowed from psychology.
As per the Authors, In addition to explainability, conveying uncertainty can be a significant contributor to ensuring trust in ML pipelines. There has been a lot of research going on in the field of explainable AI/ML, but conveying uncertainty is equally important. Explainability can not be perfect as it will have a component of uncertainty in it.
I am listing the recommendations directly from the paper. It highlights most of the learnings from the paper.
-
Use assertions to track data quality across the enterprise. This is crucial since ML models can be so dependent on faulty or noisy data, and suitable checks and balances can ensure a safe operating environment for ML algorithms.
-
Document data lineage along with transformations to support the creation of ‘audit trails’ so models can be situated back in time and in specific data slices for re-training or re-tuning.
-
Use ensembles to maintain a palette of models including remedial and compensatory pipelines in the event of errors. Track model histories through the lifecycle of an application.
-
Ensure human-in-the-loop operational capability at multiple levels.
All credit goes to the authors of this paper. I just tried to list down the vital points related to my work. Do give a read to the paper.
Thanks!!


Leave a comment